Dharani Suresh
API Project - Get started with open reproducible science! 🔬🚀
-
What is Open Reproducible Science? - In my understanding, open reproducible science refers to the practice of conducting scientific research in a way that others can easily access, replicate, and validate the findings. This approach promotes transparency and accountability in research by making methodologies, data, and results freely available.
-
Example: Git and GitHub support open reproducible science by providing tools for version control and collaboration, allowing researchers to share their code, track changes, and manage contributions transparently. This infrastructure enables the scientific community to review, replicate, and build upon work, thus fostering a collaborative and open scientific environment.
What is Machine Readable Name - The Jupyter Notebook file “Get Started with Open Reproducible Science!.ipynb” has a machine-readable name. The format “.ipynb” indicates it is a Jupyter Notebook, and the rest of the filename, though human-friendly with spaces and punctuation, is still readable by machines which can interpret it as a string for file operations and display purposes. Renamed the filename as madison_timeseries for easier understanding.
Here are some suggestions for creating readable, well-documented scientific workflows that are easier to reproduce
Write clean code by:
- Using meaningful and descriptive names for variables, functions, and classes to make the code easier to understand and maintain.
- Keeping functions short and focused on a single task, which enhances readability and simplifies debugging.
- Consistently using comments and documentation to explain the purpose and functionality of the code, aiding future maintainers and contributors.
Advantages of clean code include:
- Easier maintenance and debugging as cleaner, simpler code reduces the complexity that can obscure bugs.
- Enhanced collaboration since clean code is easier for other developers to read, understand, and contribute to.
- Increased efficiency in development cycles, with developers spending less time deciphering the existing codebase, allowing for quicker enhancements and fixes.
Getting Started with the Project
This project focuses on utilizing the National Centers for Environmental Information (NCEI) Access Data Service, which offers a RESTful application programming interface (API). This API allows users to access and subset data by applying a specific set of parameters to the version 1 (v1) URL. More information can be found here: https://www.ncei.noaa.gov/support/access-data-service-api-user-documentation
The Global Historical Climatology Network - Daily (GHCNd) is maintained by the National Climatic Data Center (NCDC), part of the National Oceanic and Atmospheric Administration (NOAA). The dataset includes daily climate records from thousands of land-based stations worldwide, spanning from the mid-1700s to the present. Temperatures in the GHCNd are primarily recorded in degrees Celsius, though historical data may also include records in Fahrenheit. Data are collected using standardized instruments and techniques at meteorological stations globally, ensuring consistency and reliability across measurements.
Citation: Menne, M.J., I. Durre, B. Korzeniewski, S. McNeal, K. Thomas, X. Yin, S. Anthony, R. Ray, R.S. Vose, B.E. Gleason, and T.G. Houston, 2012d: Global Historical Climatology Network - Daily (GHCN-Daily), Version 3. NOAA National Climatic Data Center. http://doi.org/10.7289/V5D21VHZ.
Programming Part Begins
import pandas as pd
University of Wisconsin Outline Map
University of Wisconsin Outline Map
Loading the URL
Downloading daily summaries from the University of Wisconsin-Madison station, from 1971 to the present, to analyze precipitation and temperature trends using APIs from the National Centers for Environmental Information (NCEI), a part of the National Oceanic and Atmospheric Administration (NOAA) website.
uwm_url = (
'https://www.ncei.noaa.gov/access/services/data/v1?'
'dataset=daily-summaries&dataTypes=TOBS,PRCP&'
'stations=USC00470273&startDate=1971-10-01&endDate=2024-04-05&'
'includeStationName=true&includeStation'
'Location=1&units=metric')
uwm_url
'https://www.ncei.noaa.gov/access/services/data/v1?dataset=daily-summaries&dataTypes=TOBS,PRCP&stations=USC00470273&startDate=1971-10-01&endDate=2024-04-05&includeStationName=true&includeStationLocation=1&units=metric'
madison_df = pd.read_csv(
uwm_url, index_col='DATE', parse_dates=True, na_values='NaN')
madison_df
| STATION | NAME | LATITUDE | LONGITUDE | ELEVATION | PRCP | TOBS | |
|---|---|---|---|---|---|---|---|
| DATE | |||||||
| 1971-10-01 | USC00470273 | UW ARBORETUM MADISON, WI US | 43.04118 | -89.42872 | 265.2 | 0.0 | 24.4 |
| 1971-10-02 | USC00470273 | UW ARBORETUM MADISON, WI US | 43.04118 | -89.42872 | 265.2 | 0.0 | 19.4 |
| 1971-10-03 | USC00470273 | UW ARBORETUM MADISON, WI US | 43.04118 | -89.42872 | 265.2 | 3.8 | 19.4 |
| 1971-10-04 | USC00470273 | UW ARBORETUM MADISON, WI US | 43.04118 | -89.42872 | 265.2 | 0.5 | 11.1 |
| 1971-10-05 | USC00470273 | UW ARBORETUM MADISON, WI US | 43.04118 | -89.42872 | 265.2 | 0.3 | 15.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 2024-04-01 | USC00470273 | UW ARBORETUM MADISON, WI US | 43.04118 | -89.42872 | 265.2 | 0.0 | 3.3 |
| 2024-04-02 | USC00470273 | UW ARBORETUM MADISON, WI US | 43.04118 | -89.42872 | 265.2 | 12.4 | 3.3 |
| 2024-04-03 | USC00470273 | UW ARBORETUM MADISON, WI US | 43.04118 | -89.42872 | 265.2 | 56.6 | 1.1 |
| 2024-04-04 | USC00470273 | UW ARBORETUM MADISON, WI US | 43.04118 | -89.42872 | 265.2 | 1.0 | 1.1 |
| 2024-04-05 | USC00470273 | UW ARBORETUM MADISON, WI US | 43.04118 | -89.42872 | 265.2 | 0.0 | 2.8 |
18998 rows × 7 columns
# Data was imported into a pandas DataFrame
type(madison_df)
pandas.core.frame.DataFrame
madison_df = madison_df[['PRCP', 'TOBS']]
madison_df
| PRCP | TOBS | |
|---|---|---|
| DATE | ||
| 1971-10-01 | 0.0 | 24.4 |
| 1971-10-02 | 0.0 | 19.4 |
| 1971-10-03 | 3.8 | 19.4 |
| 1971-10-04 | 0.5 | 11.1 |
| 1971-10-05 | 0.3 | 15.0 |
| ... | ... | ... |
| 2024-04-01 | 0.0 | 3.3 |
| 2024-04-02 | 12.4 | 3.3 |
| 2024-04-03 | 56.6 | 1.1 |
| 2024-04-04 | 1.0 | 1.1 |
| 2024-04-05 | 0.0 | 2.8 |
18998 rows × 2 columns
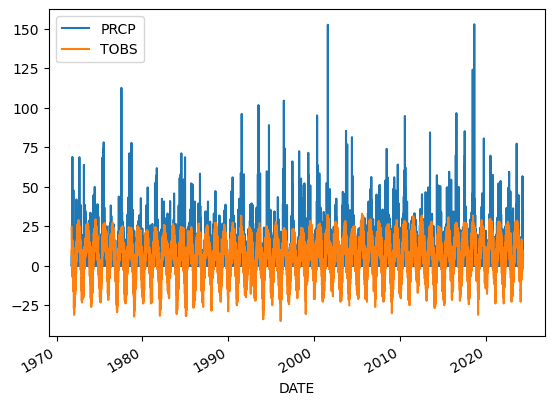
Plotting the Precpitation column (PRCP) and Observed Temperature( TOBS) vs Time to explore the data
madison_df.plot()
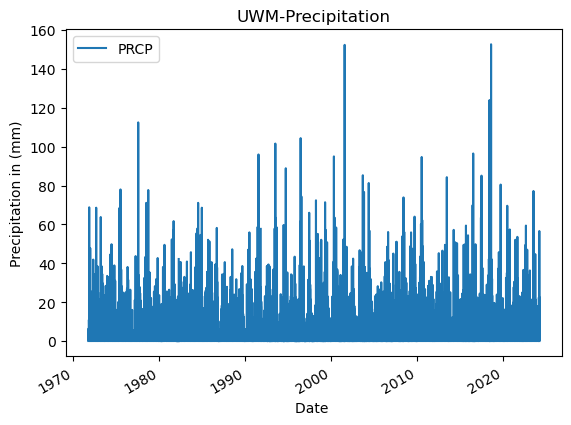
Plotting the only the Precpitation column (PRCP) vs Time to explore the data
# Plot the data using .plot
madison_df.plot(
y='PRCP',
title='UWM-Precipitation',
xlabel='Date ',
ylabel='Precipitation in (mm)')
Converting to Celsius - a Vectortized Operation
madison_df.loc[:,'TFah'] = (madison_df.loc[:,'TOBS'] * (9 / 5)) + 32
madison_df
/tmp/ipykernel_36403/3593513323.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
madison_df.loc[:,'TFah'] = (madison_df.loc[:,'TOBS'] * (9 / 5)) + 32
| PRCP | TOBS | TFah | |
|---|---|---|---|
| DATE | |||
| 1971-10-01 | 0.0 | 24.4 | 75.92 |
| 1971-10-02 | 0.0 | 19.4 | 66.92 |
| 1971-10-03 | 3.8 | 19.4 | 66.92 |
| 1971-10-04 | 0.5 | 11.1 | 51.98 |
| 1971-10-05 | 0.3 | 15.0 | 59.00 |
| ... | ... | ... | ... |
| 2024-04-01 | 0.0 | 3.3 | 37.94 |
| 2024-04-02 | 12.4 | 3.3 | 37.94 |
| 2024-04-03 | 56.6 | 1.1 | 33.98 |
| 2024-04-04 | 1.0 | 1.1 | 33.98 |
| 2024-04-05 | 0.0 | 2.8 | 37.04 |
18998 rows × 3 columns
Another Efficient Method: Creating a “Function” to Convert the Observed Temperature Values From Fahrenheit to Celsius
def convert_to_celsius(fahrenheit):
"""Convert temperature from Fahrenheit to Celsius."""
return (fahrenheit - 32) * 5 / 9
madison_df['celsius_column'] = madison_df['TOBS'].apply(convert_to_celsius)
madison_df
/tmp/ipykernel_36403/1707990930.py:7: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
madison_df['celsius_column'] = madison_df['TOBS'].apply(convert_to_celsius)
| PRCP | TOBS | TFah | celsius_column | |
|---|---|---|---|---|
| DATE | ||||
| 1971-10-01 | 0.0 | 24.4 | 75.92 | -4.222222 |
| 1971-10-02 | 0.0 | 19.4 | 66.92 | -7.000000 |
| 1971-10-03 | 3.8 | 19.4 | 66.92 | -7.000000 |
| 1971-10-04 | 0.5 | 11.1 | 51.98 | -11.611111 |
| 1971-10-05 | 0.3 | 15.0 | 59.00 | -9.444444 |
| ... | ... | ... | ... | ... |
| 2024-04-01 | 0.0 | 3.3 | 37.94 | -15.944444 |
| 2024-04-02 | 12.4 | 3.3 | 37.94 | -15.944444 |
| 2024-04-03 | 56.6 | 1.1 | 33.98 | -17.166667 |
| 2024-04-04 | 1.0 | 1.1 | 33.98 | -17.166667 |
| 2024-04-05 | 0.0 | 2.8 | 37.04 | -16.222222 |
18998 rows × 4 columns
Next, Subsetting and Resampling
# Subsetting the data to look at 1972-2023
madison_1971_2024 = madison_df.loc['1972-10-1':'2023-09']
madison_1971_2024
| PRCP | TOBS | TFah | celsius_column | |
|---|---|---|---|---|
| DATE | ||||
| 1972-10-01 | 0.0 | 11.1 | 51.98 | -11.611111 |
| 1972-10-02 | 0.0 | 12.8 | 55.04 | -10.666667 |
| 1972-10-03 | 0.0 | 15.0 | 59.00 | -9.444444 |
| 1972-10-04 | 0.0 | 13.9 | 57.02 | -10.055556 |
| 1972-10-05 | 0.3 | 15.0 | 59.00 | -9.444444 |
| ... | ... | ... | ... | ... |
| 2023-09-26 | 41.4 | 16.7 | 62.06 | -8.500000 |
| 2023-09-27 | 16.3 | 17.2 | 62.96 | -8.222222 |
| 2023-09-28 | 5.8 | 17.2 | 62.96 | -8.222222 |
| 2023-09-29 | 0.0 | 14.4 | 57.92 | -9.777778 |
| 2023-09-30 | 0.0 | 18.9 | 66.02 | -7.277778 |
18457 rows × 4 columns
Getting into Action: Calculating Annual Statistics
# Resampling the data to look at yearly mean values
madison_yearly_mean = madison_1971_2024.resample('YS-OCT').mean()
madison_yearly_mean
| PRCP | TOBS | TFah | celsius_column | |
|---|---|---|---|---|
| DATE | ||||
| 1972-10-01 | 2.920548 | 7.287535 | 45.117562 | -13.729147 |
| 1973-10-01 | 2.566027 | 7.002755 | 44.604959 | -13.887358 |
| 1974-10-01 | 2.968767 | 6.746006 | 44.142810 | -14.029997 |
| 1975-10-01 | 1.844262 | 7.629363 | 45.732853 | -13.539243 |
| 1976-10-01 | 2.204658 | 4.433058 | 39.979504 | -15.314968 |
| 1977-10-01 | 3.201918 | 5.011570 | 41.020826 | -14.993572 |
| 1978-10-01 | 2.180274 | 3.774451 | 38.794011 | -15.680861 |
| 1979-10-01 | 2.485886 | 4.058683 | 39.305629 | -15.522954 |
| 1980-10-01 | 2.470685 | 5.063611 | 41.114500 | -14.964660 |
| 1981-10-01 | 2.398305 | 4.194521 | 39.550137 | -15.447489 |
| 1982-10-01 | 2.479452 | 6.361370 | 43.450466 | -14.243683 |
| 1983-10-01 | 2.602192 | 4.321038 | 39.777869 | -15.377201 |
| 1984-10-01 | 2.780822 | 5.363736 | 41.654725 | -14.797924 |
| 1985-10-01 | 3.172603 | 5.015068 | 41.027123 | -14.991629 |
| 1986-10-01 | 2.191185 | 6.076584 | 42.937851 | -14.401898 |
| 1987-10-01 | 2.171513 | 6.437982 | 43.588368 | -14.201121 |
| 1988-10-01 | 2.013736 | 4.522253 | 40.140055 | -15.265415 |
| 1989-10-01 | 2.181267 | 5.444413 | 41.799944 | -14.753104 |
| 1990-10-01 | 2.516022 | 5.816898 | 42.470416 | -14.546168 |
| 1991-10-01 | 2.531285 | 4.675900 | 40.416620 | -15.180055 |
| 1992-10-01 | 3.600852 | 4.688068 | 40.438523 | -15.173295 |
| 1993-10-01 | 2.376945 | 3.664286 | 38.595714 | -15.742063 |
| 1994-10-01 | 2.036034 | 5.166289 | 41.299320 | -14.907617 |
| 1995-10-01 | 2.562319 | 2.915864 | 37.248555 | -16.157853 |
| 1996-10-01 | 2.469405 | 3.791136 | 38.824044 | -15.671591 |
| 1997-10-01 | 2.793220 | 6.330086 | 43.394155 | -14.261063 |
| 1998-10-01 | 2.805460 | 7.214245 | 44.985641 | -13.769864 |
| 1999-10-01 | 3.209167 | 7.580737 | 45.645326 | -13.566257 |
| 2000-10-01 | 2.826761 | 6.382051 | 43.487692 | -14.232194 |
| 2001-10-01 | 2.386197 | 7.484000 | 45.471200 | -13.620000 |
| 2002-10-01 | 2.015000 | 5.741399 | 42.334519 | -14.588111 |
| 2003-10-01 | 2.911175 | 5.942604 | 42.696686 | -14.476331 |
| 2004-10-01 | 1.824910 | 8.289510 | 46.921119 | -13.172494 |
| 2005-10-01 | 2.721751 | 7.068091 | 44.722564 | -13.851060 |
| 2006-10-01 | 2.964124 | 7.038028 | 44.668451 | -13.867762 |
| 2007-10-01 | 3.238997 | 6.161972 | 43.091549 | -14.354460 |
| 2008-10-01 | 2.735028 | 5.191061 | 41.343911 | -14.893855 |
| 2009-10-01 | 3.396953 | 7.060388 | 44.708698 | -13.855340 |
| 2010-10-01 | 2.376667 | 5.762259 | 42.372066 | -14.576523 |
| 2011-10-01 | 2.072253 | 8.368579 | 47.063443 | -13.128567 |
| 2012-10-01 | 3.528219 | 5.908564 | 42.635414 | -14.495242 |
| 2013-10-01 | 2.637363 | 4.241944 | 39.635500 | -15.421142 |
| 2014-10-01 | 2.476880 | 5.777135 | 42.398843 | -14.568258 |
| 2015-10-01 | 3.344413 | 8.461878 | 47.231381 | -13.076734 |
| 2016-10-01 | 3.355989 | 7.616809 | 45.710256 | -13.546217 |
| 2017-10-01 | 4.053444 | 7.053315 | 44.695967 | -13.859269 |
| 2018-10-01 | 3.384807 | 7.122715 | 44.820886 | -13.820714 |
| 2019-10-01 | 2.779396 | 9.043213 | 48.277784 | -12.753770 |
| 2020-10-01 | 2.087945 | 7.714641 | 45.886354 | -13.491866 |
| 2021-10-01 | 2.500275 | 7.631476 | 45.736657 | -13.538069 |
| 2022-10-01 | 2.490685 | 8.897534 | 48.015562 | -12.834703 |
Plotting the Resampled Data
# Plotting mean annual temperature values
# Plotting the data using .plot
import matplotlib.pyplot as plt
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(10, 4)) # Create a figure with two subplots
# Plot the first dataframe
madison_df.plot(
y='TFah',
title='UWM-Mean Annual Temperature',
xlabel='Date',
ylabel='Temp in (F)',
ax=axes[0] # This tells the plot to use the first subplot
)
# Plot the second dataframe
madison_yearly_mean.plot(
y='TFah',
title='UWM-Mean Annual Temperature',
xlabel='Date',
ylabel='Temp in (F)',
ax=axes[1] # This tells the plot to use the second subplot
)
fig.tight_layout() # Adjusts plot to ensure everything fits without overlap
plt.show() # Display the plots
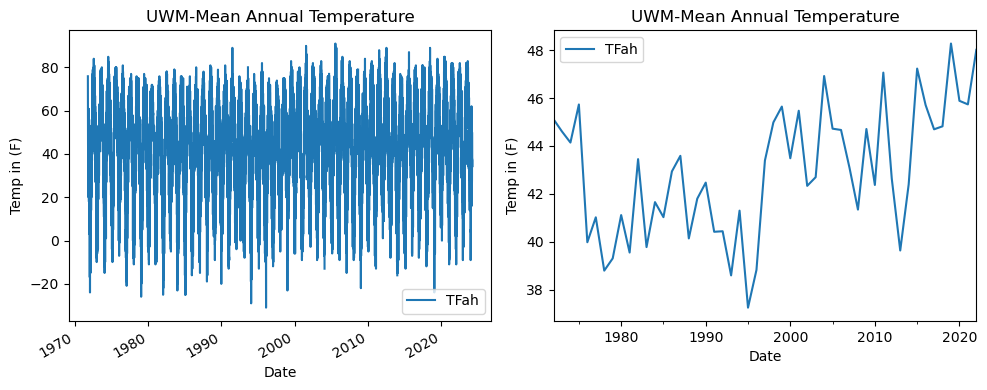
About University of Wisconsin-Madison Station Temperature Plot 📰 🗞️ 📻
University of Wisconsin-Madison shows a warming trend with increased temperature fluctuations since 1980. Recent decades at the University of Wisconsin-Madison indicate a rise in mean annual temperatures, signaling a possible long-term climate shift.
Converting into Markdown file to link with my GitHub bio page ⭐
%%capture
%%bash
jupyter nbconvert "madison_timeseries.ipynb" --to markdown